Processando a Planilha de dados fundamentalistas do Site Eu Quero Investir (EQI)
ciencia de dados, investimentos ·Com o objetivo de demonstrar como usar o Python para obter dados que possam ser usados em suas Analises fundamentalista, auxiliando na escolha do melhor investimento, apresento este pequena coleção de tutoriais, que se inicia obtendo dados de uma planilha distribuida gratuitamente pela EQI Investimentos. Apresento aqui passo a passo de como obter a planilha de forma programática e analisa-la usando recursos do Python com módulos como Panda e Nunpy.
Como o intitúito educacional, tal tutorial não exaure as possibilidades de análise e fontes de dados, o aluno deverá se basear nestes primeiros exemplos para obter seus primeiros dados para Análise Fundamentalista, buscando ampliar suas fontes, que serão sugerida no final do tutorial.
Outros tutoriais virão na sequência deste, alguns serão baseados nas dúvidas apresentadas, portanto procure comentar como foi seu aprendizado e apresentar suas dúvidas, assim posso ampliar o conteúdo e fazer novos tutoriais. Caso prefira falar comigo diretamente use o Whatsapp (85) 985205490 ou o e-mail nizin.invest@gmail.com
Lembrando que este tutorial não é uma recomendação de compra e venda de ações, apenas um tutorial de como usar o python e fazer Analise Fundamentalista.
Como executar os comandos no Python
Você poderá escrever todo o código em um arquivo e executar com o comando python nome_do_arquivo.py ou poderá ir digitando comando a comando no interpretador do Python, nos tutoriais mais avançados algumas vezes usaremos o Jupyter no VSCode. Para mais detalhes veja nosso curso básico de Python.
Eu criei um arquivo [requirements.txt que pode ser baixando] com as bibliotecas que usamos aqui, assim, basta usa-lo para instalar todas com o comando pip install -r requirements.txt
As bibliotecas que usaremos são:
- GSpread
- Pandas
- NunPy
- MathPlotLib 3.2.2
- openpyxl
- requests
- pyfolio
Para sucesso na instalação do MathPlotLib 3.2.2, defina a variável de ambiente MPLLOCALFREETYPE=1
Outra forma de instala-las é uma a uma com os comandos:
1
2
3
4
5
6
7
8
pip install gspread
pip install pandas
pip install Nunpy
pip install mathplotlib=3.2.2
pip install jinja2
pip install openpyxl
pip install requests
pip install pyfolio
Um pouco sobre as principais módulos
Iremos manter o foco em dois módulos nesta etapa, os demais irão ser explicadas nos outros artigos desta série conforme forem demandados, mas se quiser aprofundar em cada um veja os cursos de Python Básico e Avançado que oferecemos.
Pandas
Pandas é um módulo usado para para lidar com Data Frames de dados (Tabelas num linguajar mais popular), O pandas enriquece o python na manipulação de tabelas de dados fornecendo funções extras para manipulação de DataFrame (Tabeles), Séries de dados (similar a array), as indexações são feitas por colunas e linhas, ambas sendo manipuladas como Séries de dados.
Fácilidades como multiplicação, divisão, somatórios, produtórios de conjunto de células, são presentes e de fácil acesso, e iremos apresentar pouco a pouco nesta série de tutoriais, caso venha ter uma dúvida que demande um aprofundamento maior, use a seção de comentários para compartilhar sua dúvida.
GSpread
O GSpread é umm módulo para manipular planilhas eletrônicas do Google Drive, Não iremos aprofundar no seu uso aqui, mas sempre que demandar iremos detalhar as funções utilizadas.
Vamos começar!
Crie sua credêncial de acesso ao Google API para um robô
Usaremos nossos códigos como se fosse um robô de processamento, assim ficando bem mais simples o acesso, para isso é preciso ativar serviços do Google API e criar uma credêncial que deverá ser gravada na pasta de trabalho.
Ativando os Serviços da API do Google
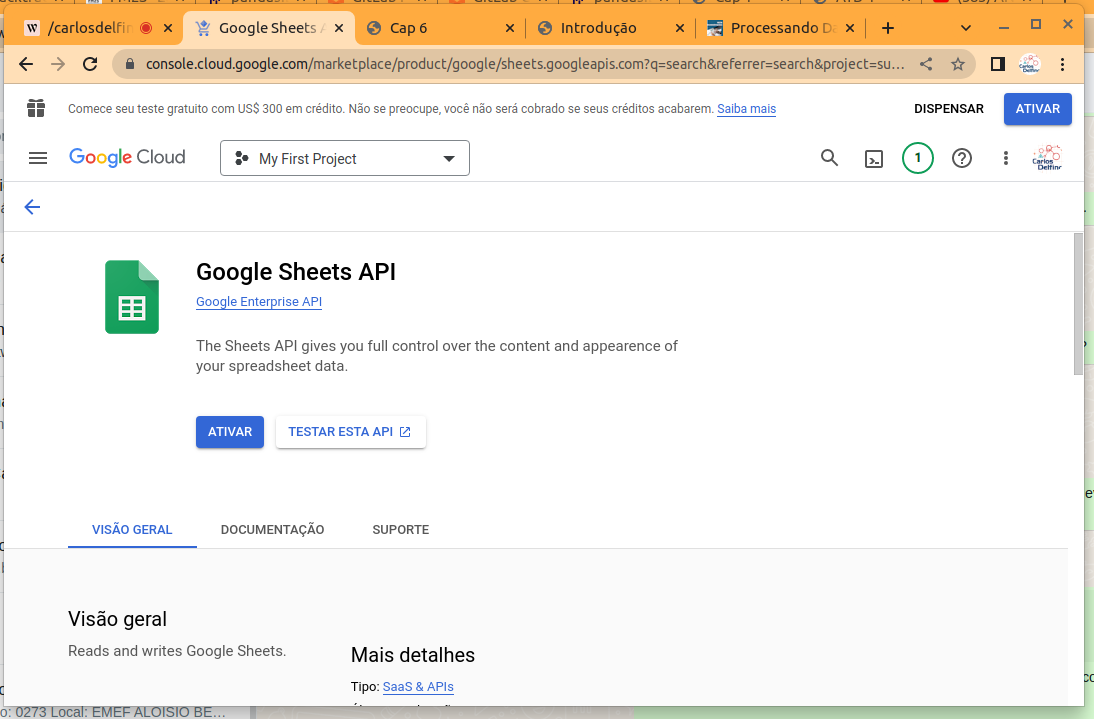
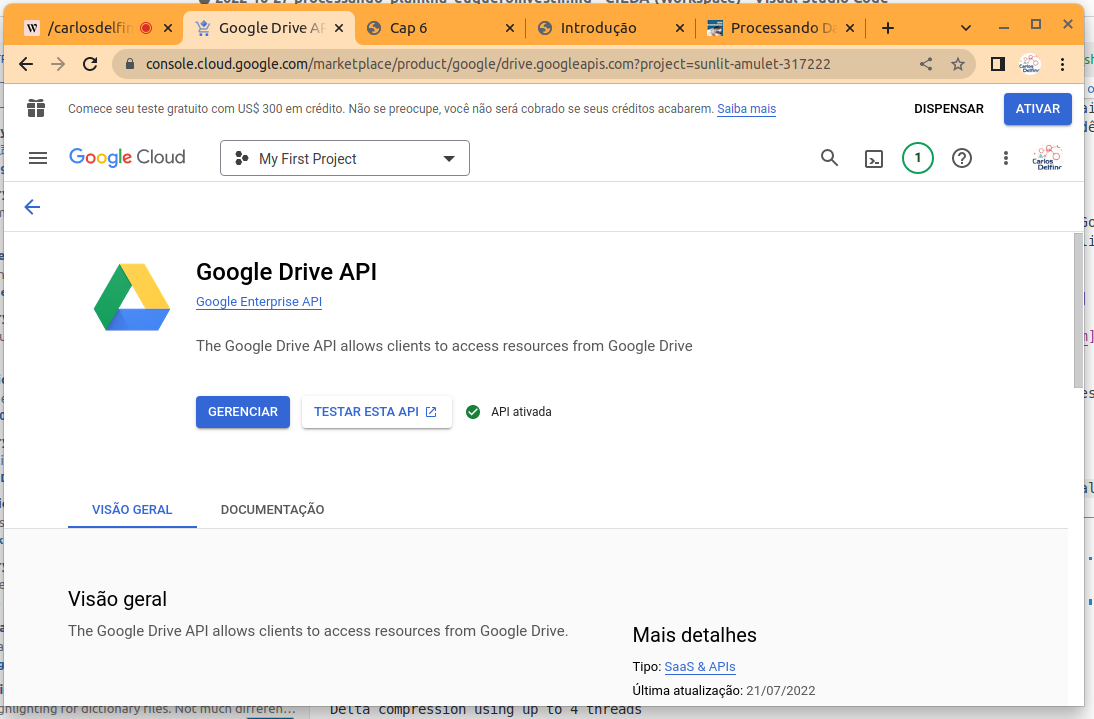
O primeiro passo é ativar a API do Google Drive e do Google Sheets em sua conta no Google, portanto você já deve ter um e-mail no GMail, para ativar as APIs siga cada um dos links e clique em ativar, são dois links distintos apesar de bastante similares:
- https://console.cloud.google.com/marketplace/product/google/drive.googleapis.com
- https://console.cloud.google.com/marketplace/product/google/sheets.googleapis.com
Irei mostrar abaixo as telas apenas da ativação da API do Google Sheet, pois o processo é identico para ambos.
Criando a Credêncial de acesso
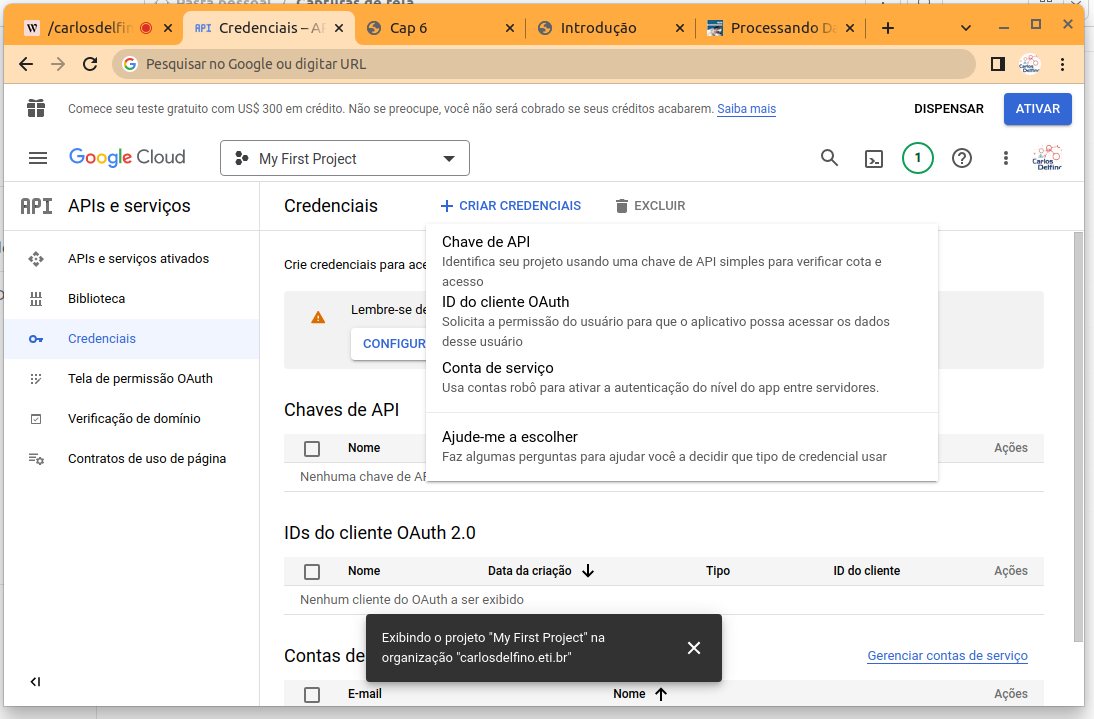
Agora vamos criar as credênciais propriamente, para isso entre no link:
-
A credêncial a ser criada é para Bot (Robô), no menu está como “Conta de Serviço”, para cria-la clique no botão “Criar Credênciais” em seguida escolha “Conta de Serviços”.
-
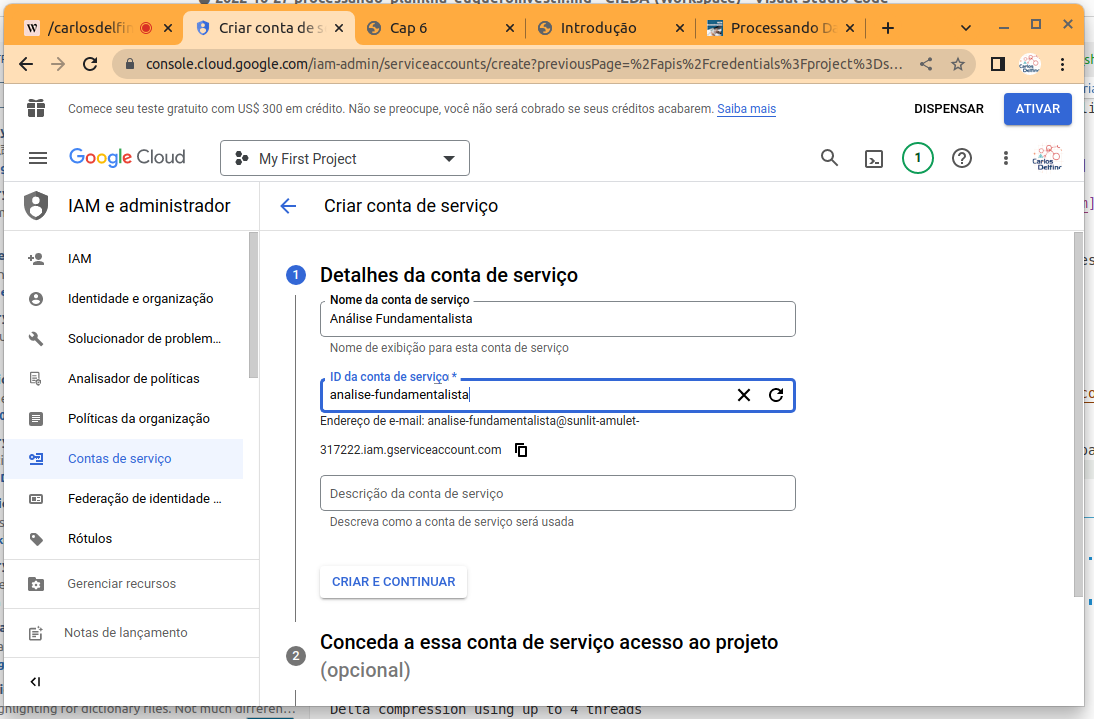
Digite o nome que deseja dar a credêncial que está criando, pode ser o nome de seu projeto que irá usa-la.
-
Em seguida defina o papel como sendo “proprietário”, clique em continuar
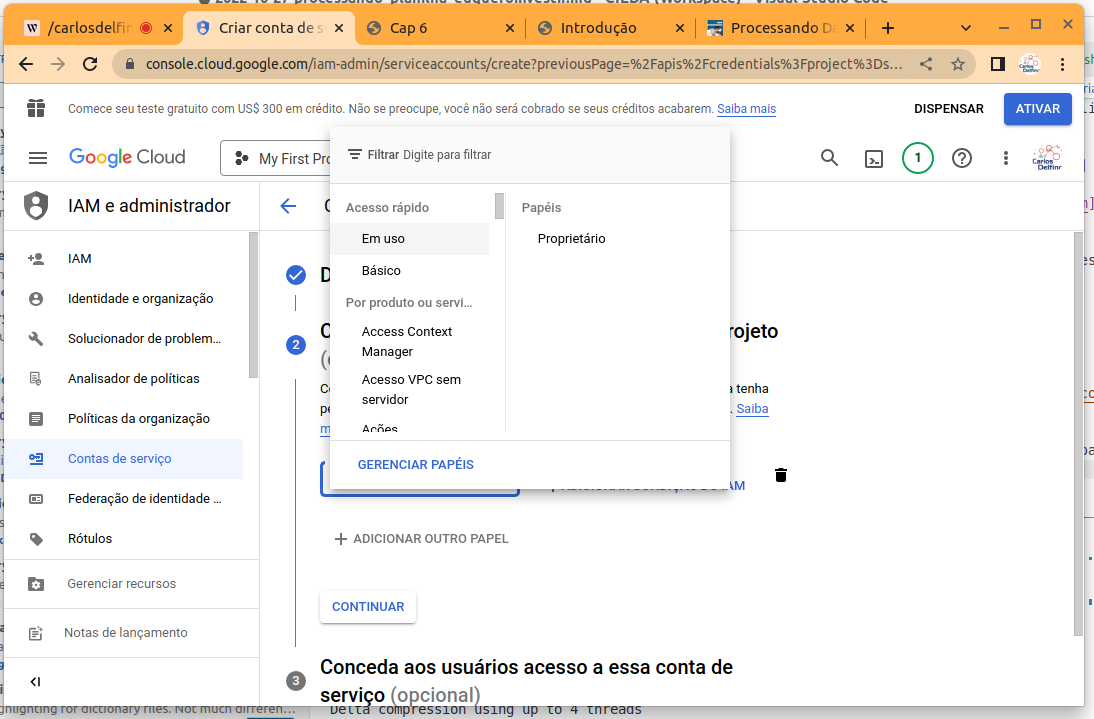
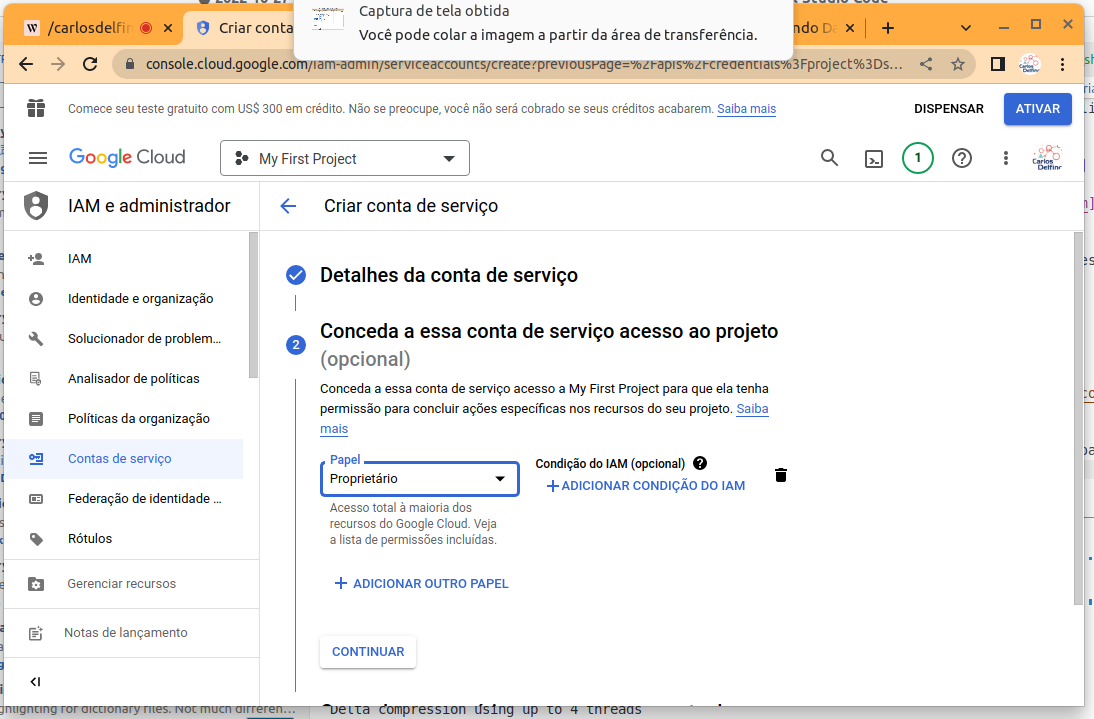
- Nesta tela clique em continuar sem alterar nada.
- Agora role a tela até a base e clique no lápis correspondente na “Conta de Serviço” criada.
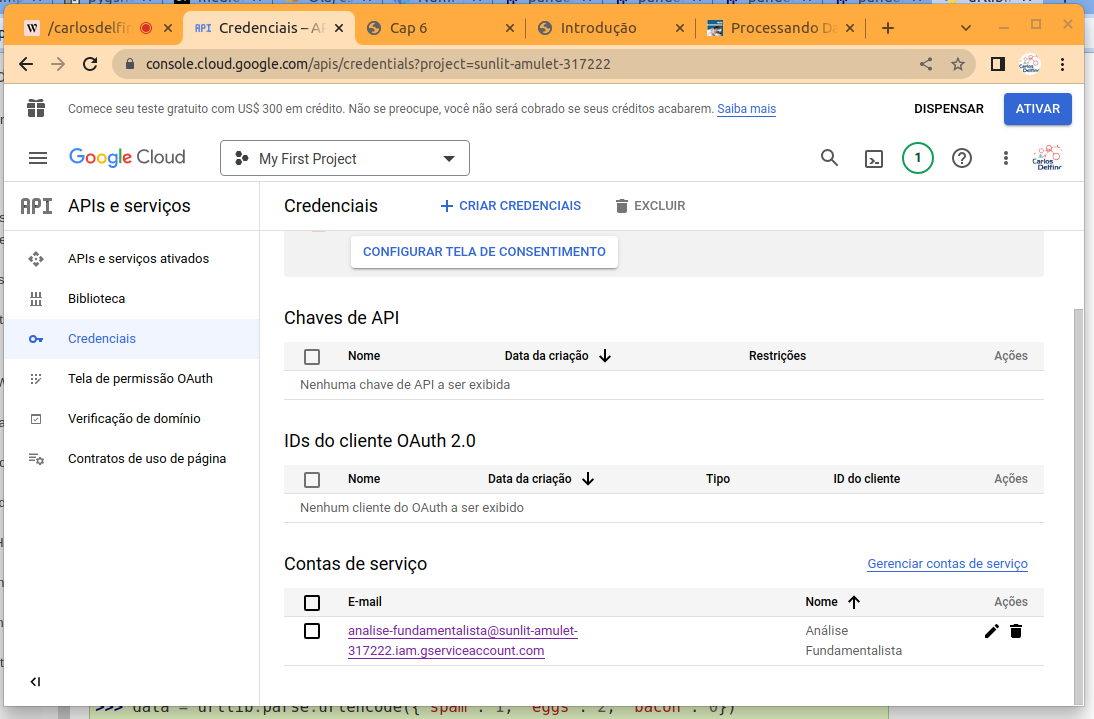
- Em seguida vá na aba chaves e clique no botão “Adicionar Chave” e selecione “Criar Nova Chave”.
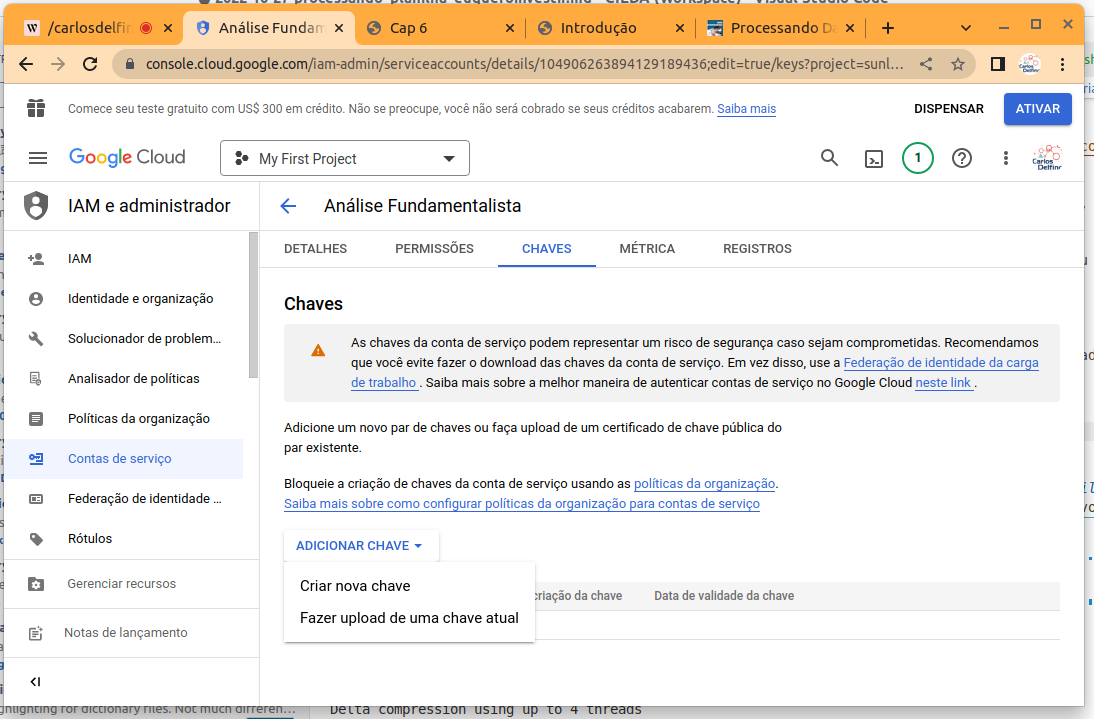
- Na tela apresentada selecione a opção “JSon” e clique em “Criar”.
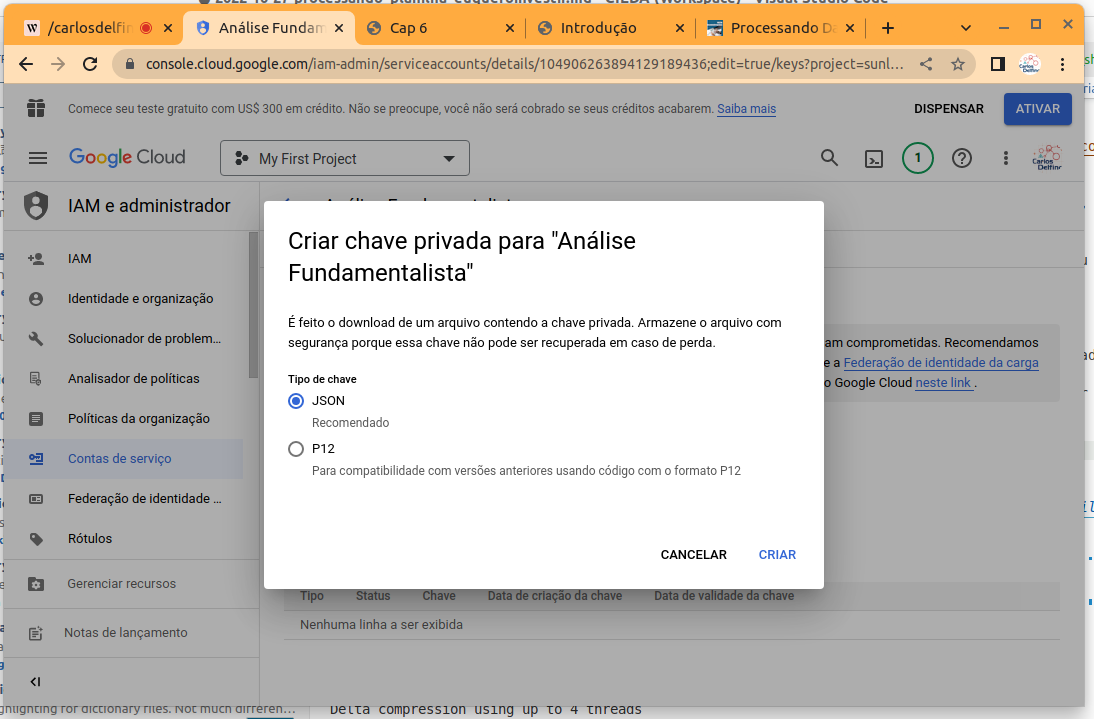
- Neste momento um arquivo será criado e baixado, clique em fechar, e mova o arquivo para a pasta que usará para digitar os comandos deste tutorial.
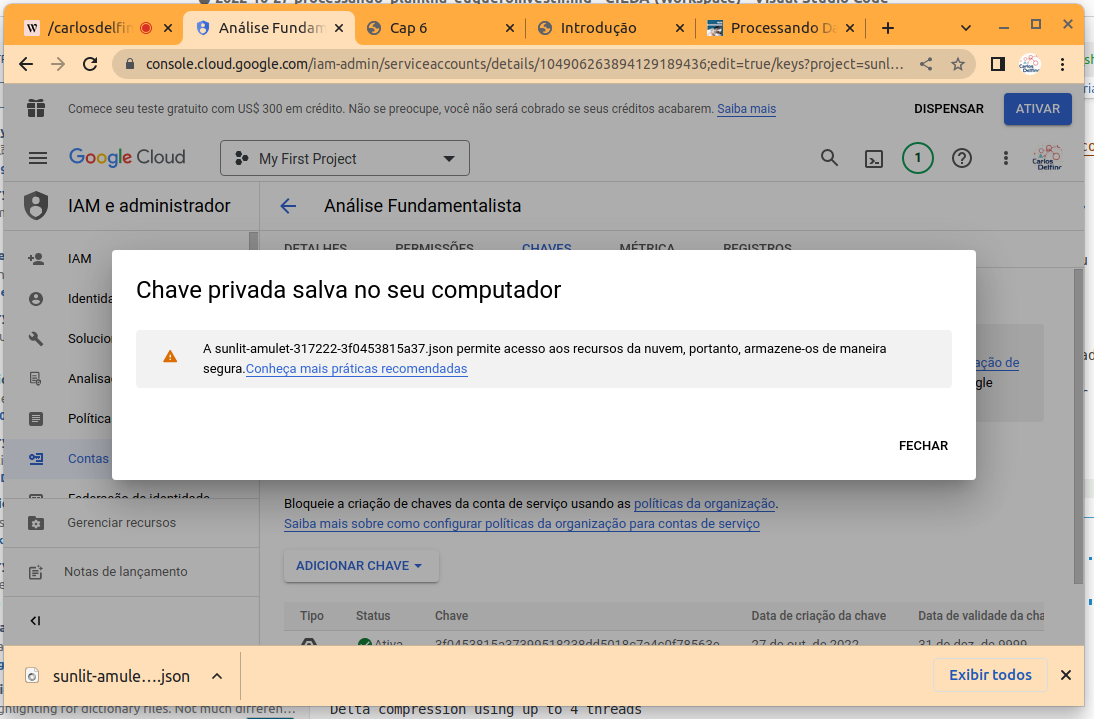
- Renomeie o arquivo para “service-account.json”
Para uso em outros cenários, reserve o e-mail encontrado na propriedade client_email do arquivo json que foi criado. Renomeie o arquivo para service_account.json e mova-o para o diretório que irá trabalhar.
Conecte-se na planilha que deseja trabalhar
Existe vários módulos python para acesso as plailhas do Google, usaremos o gspread que é suficiente para nosso interesse educacional, mas você pode, quando já estiver entendendo as práticas aqui apresentadas, usar outro como o pygsheets.
Para conectar no Google Drive e a abrir a planilha, você deve já ter criado suas credênciais como descrito acima, então selecione a planilha que deseja trabalhar, ela deve ser acessível ao e-mail que representa as credênciais criadas, no nosso caso a planilha que usaremos é compartilhada públicamente com base no link, sendo assim basta termos o ID da planilha original.
Você pode fazer uma cópia para sua conta seguindo o link: https://docs.google.com/spreadsheets/d/1feSww8-_w1aF2xkBChoSMY5Dbq-UQtZTDEBFmmbBckw/copy, lembre-se de compartilha-la com o e-mail reservado acima ou torna-la pública, para que seja possível acessa-la com seu código de análise. Também é preciso que reserve o ID da planilha que pode ser obtido na própria URL, usaremos aqui este ID já que ela é de acesso público, mas você pode substituir para o ID de sua própria planilha.
1
2
3
import gspread as gs
gc = gs.service_account(filename="./service_account.json")
planilha = gc.open_by_key('1feSww8-_w1aF2xkBChoSMY5Dbq-UQtZTDEBFmmbBckw')
Há duas outras formas de abrir a planilha, pelo nome e pela URL, pesquise nos manuais do gspread para mais detalhes.
Obtendo a página da planilha para obter nossos dados
Nesta planilha há várias páginas (Worksheets), usaremos a primeira apenas, nomeada como “Capa”, sendo assim use o seguinte comando para obter a página com todos os dados e informações de sua planilha, veja que, o nome da planilha é case sensitve:
1
capa = planilha.worksheet("Capa")
Obtendos os valores
Vamos obter todos os valores das células e em seguida remover o que não precisamos, identificar os cabeçalhos e index das linhas que em nosso caso serão os nomes (Tickets) das ações.
Lembre-se que as listas e matrizes são indexadas apartir de 0.
Descartando oque não é relevante
Visitando a planilha original, vemos que as 5 primeiras linhas podem ser descartadas, são o cabeçalho de apresentação da planilha, já a linha 6 é o cabeçalho propriamente de cada coluna.
Então, use o seguinte código para obter o cabeçalho das colunas e descartar de nossa matriz (capa_values) o que não precisaremos.
1
2
3
capa_values = capa.get_values()
capa_headers = capa_values[5]
capa_values = capa_values[6:]
Indexando pelos Tickets
É importante reservamos a primeira coluna para converte-la em indice das linhas, para que possamos acessar as linhas usando os Tickets (nome da ação). Lembre-se que as primeiras 6 linhas são descartáveis.
1
2
capa_tickets = capa.col_values(1)
capa_tickets = capa_tickets[6:]
Esta etapa poderia ter sido feita em apenas uma linha com capa_tickets = capa.col_values(1)[6:].
Agora que temos os indices e cada linha, podemos remover a redundância dos indices de capa_values e ajustar capa_headers, já que não precisaremos da primeira coluna mais.
1
2
3
4
for i in range(len(capa_tickets)):
del capa_values[i][0]
capa_headers = capa_headers[1:]
Criando nosso Dataframe no Pandas
E finalmente teremos um Dataframe, primeiro importamos o módulo Pandas com o aliase pd. e então informamos a matriz de dados capa_values, idendentficamos as colunas, e finalmente identificamos o indice contido em capa_tickets.
1
2
3
import pandas as pd
capa_df = pd.DataFrame(capa_values, columns=capa_headers)
capa_df.index = capa_tickets
Agora o dataframe com as colunas nomeadas com base nos valores de capa_headers e os indices identificados pelos tickets obtidos de capa_tickets.
Removendo dados inválidos e ajustando os típos de dados
Mas ainda não terminamos esta etapa de preparação dos dados, é preciso remover valores inválidos, converter valores prefixados e pósfixados como no caso de valores monetários e porcentágens já que a função gspread.get_values() não tem opção para retornar valores puros de seus formatos finais. Os valores invalidos são representados pela String #N/A, iremos substituir pelo valor 0, os demais valores terão seus sufixos removidos, e removeremos os espaços iniciais de cada objeto.
1
2
3
4
capa_df.replace(to_replace=r'#N/A', regex=True, value='0', inplace=True)
capa_df.replace(to_replace=r'R\$', regex=True, value='', inplace=True)
capa_df.replace(to_replace=r'\%', regex=True, value='', inplace=True)
capa_df.replace(to_replace=r'^ ', regex=True, value='', inplace=True)
Agora vamos ajustas os valores para notação númerica internacional, já que a planilha está nos entregando os valores decimais separos com vírgula e os milhares com ponto.
1
2
capa_df.replace(to_replace=r'\.', regex=True, value='', inplace=True)
capa_df.replace(to_replace=r',', regex=True, value='.', inplace=True)
Converteremos agora os valores para seu tipo adequado, existe uma função convert_dtypes do Pandas porém ela não consegue converter as colunas como desejamos, sendo assim, temos uma alternativa apresentada abaixo.
Veja que, primeiro pegamos as 3 primeiras colunas que são as categorias (category) e pegamos as restantes e definimos como float (float32).
1
2
3
4
5
6
7
8
capa_df_col_dic = {}
for col in capa_df.columns[0:3]:
capa_df_col_dic[col] = "category"
for col in capa_df.columns[3:]:
capa_df_col_dic[col] = "float32"
capa_df = capa_df.astype(capa_df_col_dic, errors='ignore')
Conclusão
Além deste tutorial, temos outro que visa obter os mesmos dados diretamente do site StatusInvest.
Neste tutorial você aprendeu como criar uma credêncial no Google Cloud e como obter os dados de uma planilha do Google Drive através do módulo GSpread, se familiarizou com o módulo PANDAS que permite lidar com tabelas de dados dentro do Python.
Nos próximos tutoriais você irá aprender cada vez mais sobre estes módulos e outros que serão extremamente úteis para suas Analises Fundamentalista e também Técnicas, facilitando sua tomada de decisão quanto a que ações comprar ou vender no curto, médio e longo prazo.
Referências
- CIEDA
- https://pandas.pydata.org/docs/index.html
- https://medium.com/@vince.shields913/reading-google-sheets-into-a-pandas-dataframe-with-gspread-and-oauth2-375b932be7bf
- https://practicaldatascience.co.uk/data-science/how-to-read-google-sheets-data-in-pandas-with-gspread
- https://docs.google.com/spreadsheets/d/1feSww8-_w1aF2xkBChoSMY5Dbq-UQtZTDEBFmmbBckw/copy
- https://lp.eqi.com.br/obrigado-planilha/?source=spreadsheets
- https://stackoverflow.com/questions/61213417/delete-remove-column-in-google-sheet-over-gspread-python-like-sheet-delete-row#:~:text=There%20is%20no%20method%20in,this%20with%20a%20batch%20update.
- https://stackoverflow.com/questions/18022845/pandas-index-column-title-or-name
- https://stackoverflow.com/questions/70914130/gspread-get-also-none-values-when-reading
- https://stackoverflow.com/questions/48511747/using-google-query-to-download-parts-of-a-published-sheet